Re-purpose your linear classifier - Ranking 9 to 5
Posted 12 Dec 2014
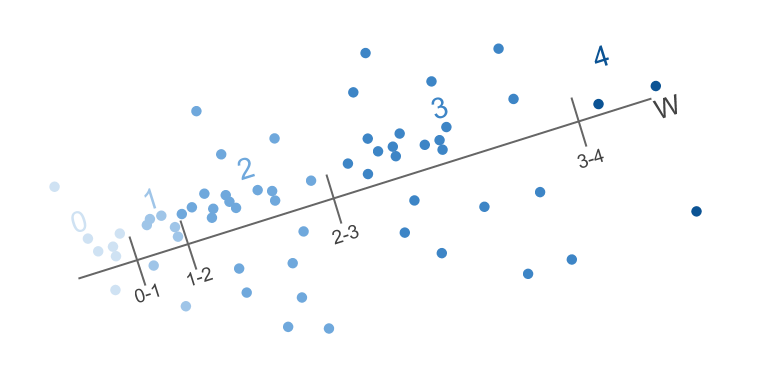
Lets say that we are in the movies recommandation business and instead of just providing yes/no recommendation we want to provide a 5 values scoring system: [“don’t bother”, “bad but watchable”, “nice”, “very nice”, “Shawshank Redemption” ]. We have this ordering in mind that movies that are “nice” are better than “don’t bother” but are worse than “very nice” and also from “Shawshank Redemption” which has a category all of its own.
These can also be treated as five ranks: [0, 1, 2, 3, 4] but the point is that if a movie get a 2 and another movie gets a 4 it does not mean that the movie is twice as better or that it is +2 better. It means that all the movies in rank 2 are better than those in categories 1 and 0 and are worse than the movies in 3 and 4.
The short version
We want the benefits of using any linear classifier that is out there in the market to solve our problem. We want to find a line such that projecting on to it will give us the best ranking, and we want to find the boundaries between the ranks. There are two trick here: splitting each sample into two new samples, and adding boundary marks: The first new sample represent its relation to the upper bounding mark and the second new sample the relation to the lower mark. Suppose our training sample x has d dimensions, and it should recieve rank 1. We create two new samples from x (and labels):
Run a linear classifier of your choosing on this transformed training set. The resulting weight vector that is trained by the classifier is a concatenation of a classifier and the 4 locations of the bounding marks.
To predict the rank of a new sample , obtain the prediction and check for the rank using the boundary marks.
The long version
Lets look at some other naïve ways to tackle ranking in a closed set:
The first thing we can do is use linear regression with the ranks as the supervision signal. Linear regression is great, it is an extremely useful and powerful tool but it has a serious downside for us: it finds a weight vector w that will actually predict the rank. For example will try to be as close a possible to the value 1, even though we are interested in the relations between the ranks and not its numerical value. In addition, if we used a different scale for our ranks for example [ 0, 4, 23, 100, 1000] we would get a very different weight vector.
Another solution would be to repurpose our classifier to rank our samples as we mention in the previous post (link). This means that we choose a pair of samples (, ) and train a classifier to predict which sample is ranked above the other. This method treats our labels correctly as ranks and not numbers which is nice. It will find a weight vector that best ranks our samples. In most application this is just fine since we are interested in recommending or not recommending. However, here we actually want to output a rank [0,5].
To tackle this we can use this method and then find our ranks on the 1 dimension of the prediction-scores. We can also train 5 different rankers one for each rank. Or even classifiers using all pairs. The downside is that we have to train multiple classifiers each of them would get a different weight vector and we will need some sort of a heuristic to combine them and make our final prediction.
However with very little effort we can do much better.
Our goal is to find both a direction w (a weight vector) on which to project our samples, and to find these boundary marks that separate the samples into their ranks.
Let’s take a look at the SVM optimization problem.
The objective has two parts the first ( ) is a regularizer on w. The second ( ) penalizes for making classification mistakes. For each sample you pay a penalty that depends on how wrong you are: You pay nothing if you classify your sample correctly with a positive margin of 1. A solution vector w will make a compromise between having a small 2-norm and making fewer mistakes
So let’s say we have a sample with rank 1. We can create two new conditions: one that says that it should be above the and one that says it should be below the . This could also be thought of as trying to make as positive as possible, and as negative as possible. So we are willing to pay a penalty if this does not happen.
These new constraints are added by creating two samples:
Notice that after we extend the dimention of x we also need to extend w
This makes .
We reduced our problem back to to the classical classification problem.
Once you classify these new samples you will need to get your weight vector back and split it back to w and the boundary marks. Then, for each new sample, you make a prediction by multiplying w with the sample, and checking between which marks the sample the prediction is located.
If a sample should be ranked using the lowest rank (or the highest) you only need to add one sample.
Some quick gains (and I am just using copy paste from the previous post):
- Easy to implement (link to python/matlab code on github).
- We optimize our classifier to solve exactly what we are looking for.
- We have the benefits of using out-of-the-box linear classifiers that are optimized to the max such as Vowpal Wabbit or Liblinear.
- We get one classifier and one prediction for each samples. No need to combine multiple predictions from different classifiers.
Things to notice:
- We pay a penalty for having boundary marks with large values. This can be addressed by normalizing the data to unit variance. Normalizing will limit the predictions and then the boundary marks will require smaller values. This will make the loss you pay for each mark relative small, especially if you have many samples and you are working in a high dimension.
- If the classifier uses a bias term (
_interceptfor python users). You will need to change the rank-prediction part to handle this. Instead of using you will need to use the prediction with the bias and then check between which two marks your prediction is located. This could also be addressed by normalizing the data to have zero mean and using the version of the classifier which does not add a bias term (note that if your data is sparse normalizing to zero mean is not recommended since it will break the sparsity).
One more thing:
Nobody is promising us that and it is possible this is not the case. We can split each sample into 5 one for each rank. This is a stronger supervision signal that might work better for some datasets. We can also add a few more sample that will provide penalties for breaking this constraint. Samples of the sort
Check out the code for this on github.