Re-purpose your linear classifier - AUC
Posted 10 Dec 2014
AUC - Area under the curve, usually refers to the area under the ROC curves. It is common practice in machine learning and in statistics to plot the ROC curves and from there gain information about the behaviour of the classifier. I would like to talk about AUC but not in the classical context of ROC curves. Another less known interpretation, is that AUC is the probability that a positive sample will receive a score higher than a negative sample.
In other words: Pick a pair of samples at random: a sample from the positive set and a sample from the negative set. Repeat this process for all possible pairs. The AUC is the fraction of pairs for which you rank the positive sample above the negative sample. Notice that there is no boundary which means that you can add +1000 to all of your predictions and the AUC will not change. This however, can break you classification which is usually determined with the confidence relevant to 0. This interpretation actually places AUC as a measurement of how well your data is ranked, less as a metric for classification.
The short version
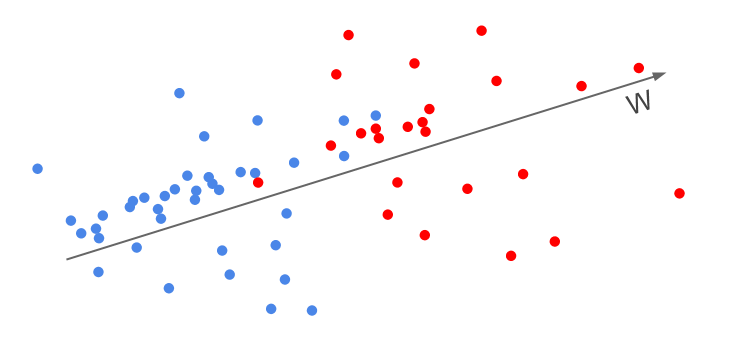
We want to find a line in that projecting on it will give us the best AUC. We do this by randomly picking two samples: one from the positive class and one from the negative class (usually it is not necessary to go over all of these pairs) and for each pair create a new sample. This new sample represent our desire that the positive-sample scores will be higher the negative-sample scores.
Lets say that is a sample from the positive class and should be ranked higher than - a sample from the negative class. We create a new sample with a positive label.
Then you run a linear classifier of your choosing. The resulting weight vector will now maximize the AUC instead of maximizing the classification accuracy.
The long version
You have probably came across AUC as a metric of goodness for classification problems. Most likely it was used in such context as “Our classes are unbalanced, we have only a fraction of positives so we could not use accuracy and we choose AUC”. AUC has this nice property that it will inherently balance the two classes. This is clear from the second AUC definition - “Choose a pair: a positive sample and a negative sample …”. Since we use pairs we will always iterate over the same number of positive and negative sample (the sample from the smaller class will just have more repeats).
Here is a toy example: you have 1 positive sample for every 99 negative samples. If you have a classifier that always return -1 than your accuracy is 99%. You might claim however, that this classifier is not what you are looking for. It is also hard to state that a classifier that learned to always return 1 actually learned something that is relevant. However, when you solve an svm classifier it is doing exactly that; it minimizes an svm-objective which is a combination of minimizing the number of classification errors and a regularization term.
There is also another key difference between AUC and accuracy and that is the number zero. When we classify stuff we are interested in the direction of our prediction relative to zero. We need a flipping point and zero is the boundary that flips the classification (it does not have to be zero but the point is that we need a flipping point). Now, for AUC we only care that a positive sample will receive a score that is higher than a negative sample. Let say we have the perfect classifier that predicts -1 for all the negative samples and +1 for all the positive samples. This classifier will have perfect AUC and accuracy. If we now create a new classifier that predicts +3 for all the negative sample and +5 (for example by changing the bias term), this new classifier will have perfect AUC but only 50% accuracy.
This is why when I think of AUC, I think of it more as ranking metric than a classification metric. Basicly, make sure that you rank the relevant stuff higher than the non-relevant.
Here is an indicator function that recieves 1 if the ranking condition is true and 0 if false.
So one thing we can do is to train a classifier and use the confidence (the distance from the margin) wTx to rank the samples. If we manage to classify the sample correctly ranking them is a simple task. While this is possible, it turns out that if our goal is rank the sample (maximize the AUC) it is just better to do it directly. This is very true in case your data is unbalanced. But even when your data is balanced you usually get better ranking results when you use algorithms which are tailored to rank. For example, in the context of websearch we are not interested at all in classification we just want that the relevant results will appear higher.
So we can tweak the SVM formulation to maximize the AUC instead of accuracy. I want to change the part that penalizes you for classification errors to penalizes for AUC error. Penalize the classifier when you give a negative sample a score that is higher than that of a positive sample.
This is the classical SVM problem:
But now let’s make so it will directly optimize AUC and not the classification accuracy. First we will notice that requesting that the classifier to classify a positive sample (p) higher than a negative sample sample (n) is the same as requiring
This is true because of the linearity of our classifier.
The next step is to create new samples for all possible pairs, new sample from the type x^{p,n} =x^p - x^n with an always positive label y^{p,n}=+1 and plug them into a classifier:
OR:
To see the direct connection to the AUC lets fix w. Now, notice that if a pair (n,p) is ranked incorrectly and we made a ranking mistake then .
This means that:
This is why what we are doing here is optimizing the AUC directly. We also pay a fine for pairs that were ranked correctly but that our certainty in their ranking did not gain a confidence larger than one. This is the added benefits that people are talking about when they mention the large margin property of SVM.
Some quick gains:
- Easy to implement (link to python/matlab code on github).
- We optimize our classifier to solve exactly what we are looking for.
- We have the benefits of using out-of-the-box linear classifiers that are optimized to the max such as Vowpal Wabbit or Liblinear.
One more thing:
What if we are in a truly online framework where we receive one new sample at time t. First, sometimes when people say online what they actually refer to is “fast classifier so I can run it on big data”. lets assume that this is not the case and you are actually in an online scenario: You receive a sample make a prediction then someone reveals the label and you can correct your classifier. Then, to maximize the AUC what you can do is to save a pool of positive samples and a pool of negative samples. Lets say that at time t a new sample arrives. You make your prediction and then you are informed that this sample is positive. What you do is you pick a negative sample at random from the negative-pool and update your classifier using as mentioned above using a sample of the sort .
Check out the code for this on github.
References: